Fast and Exact Calculating tr[H]
(ours)
概要
-
tr[H]を正確に計算する手法とその実装。
ただしHはHessianで、活性化関数は∀0<α,f(αx)=αf(x)を満たすとする
-
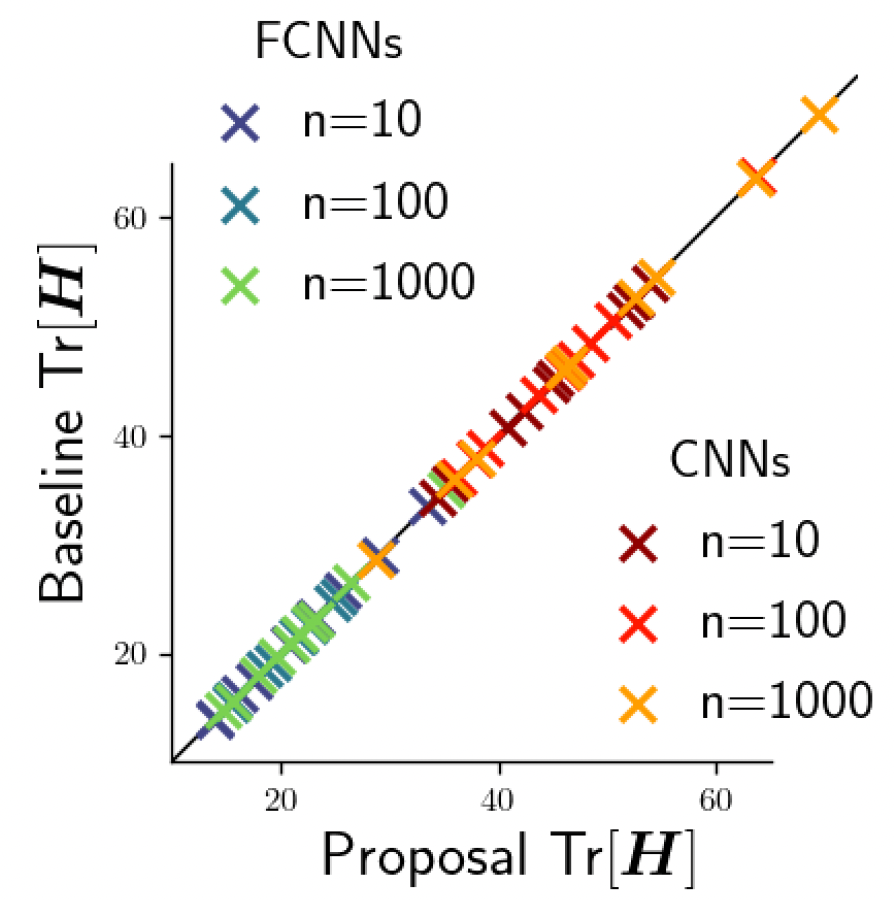
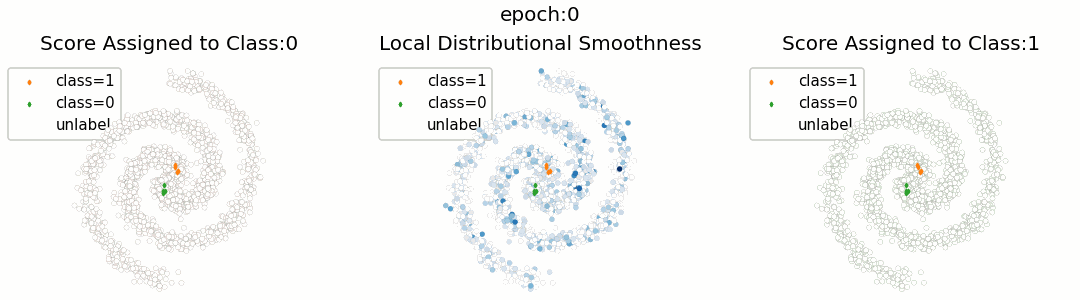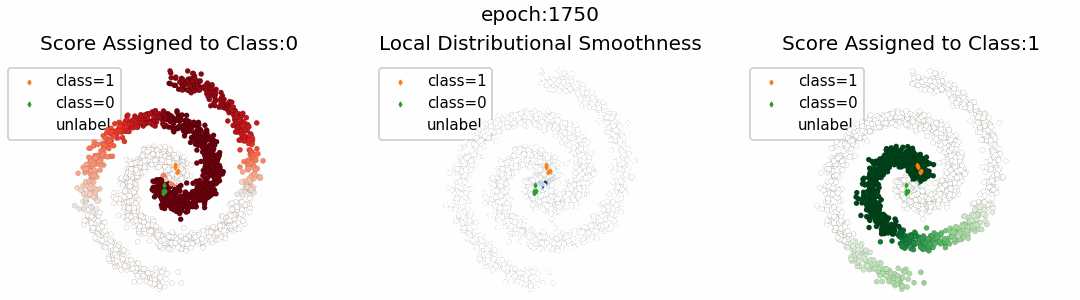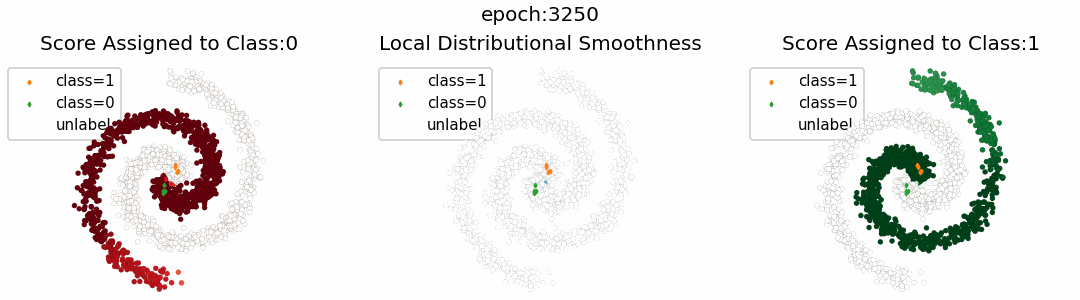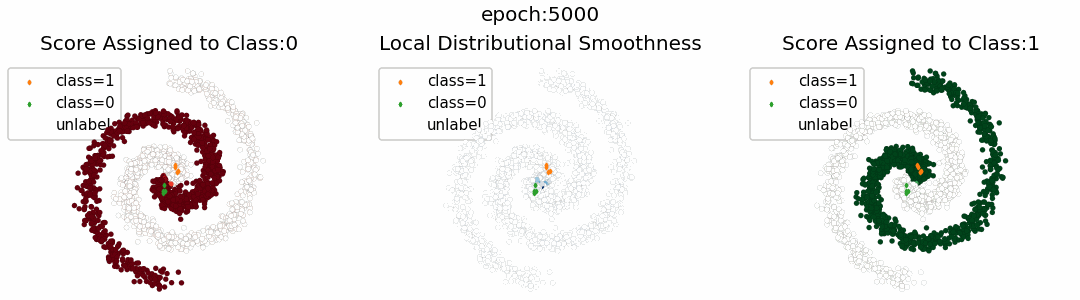
下図は、ナイーブに計算した場合との比較を示す
左図: 時間的な比較。提案手法は高速化を実現していることが分かる
右図: 出力の比較。各要素が対角にあり正確性を例証している
-
より詳細な内容は
url
を参照のこと